Status: Obsolete (as of 2010-08-16)
Steve Yegge <stevey@google.com> Last modified: 2010-08-16August 16th, 2010: This document used to be a section in the Grok Master Design Document. Grok no longer uses a Bigtable for its index.
This design, incidentally, was nice in theory and terrible in practice. We were using the bigtable to de-dupe millions of duplicate rows and columns produced by the sharded indexers. It wound up being too much data to cram into the bigtable at once, and we'd get locked out or stalled.
We solved the problem by having the indexers do some pruning, and we added a separate postprocessing pass for the merge. This was after we switched from Bigtable to sstables, so we never tested whether it would have made the Bigtable solution viable. Presumably it would, but as our index is currently read-only, sstables were a better option.

We have chosen to store Grok's index in a Bigtable. Other options included SSTables, MegaStore, a Grok-specific custom storage model atop GFS, or a relational database. We felt that among the available options Bigtable offers the best balance of simplicity, flexibility, performance, and scalability. We could in theory be talked out of using Bigtable, but it would have to be a very convincing argument.
We have two important design goals in mind for our Bigtable schema:
The particular problem we face with concurrent indexing is that many indexers may discover the same Binding or Association simultaneously.
Our first discarded design idea was to have a small number of columns representing the 25 or so well-known Association types, such as "caller", "superclass", "subclass", "parent scope", "declaring type", "method", "field", and "property". All of a Binding's Associations of a given type would be represented as protocol buffers appended to the column of that type.
For instance, the Binding for java.lang.Object would have
(among others) a column for "methods", which would contain protocol buffer
entries for java.lang.Object#toString, java.lang.Object#hashCode,
and its other methods.
The problem with this design is that many indexers would simultaneously
discover that java.lang.Object has a toString method.
To avoid having thousands of duplicate entries in the "method" column of
java.lang.Object, there seem to be two options, neither of
them especially desirable:
Transactions: an indexer would lock a row, ask the row if a particular Association entry has been recorded, and if not, record it; then unlock the row. This is of course possible to implement but would result in unfortunate lock contention and diminished throughput.
Garbage Collection: we could permit the duplicate entries, and remove them in a separate compaction pass. This could work, but seems like it might slow down the indexing and potentially use more machine resources than we need.
Since neither option seemed appealing, we are proposing a lock-free schema, in which every distinct Association instance gets its own column. Instead of 25 columns, we would have 25 column families. The full name of an Association column would be its family (e.g. "method:") and an Association-specific signature.
For bidirectional associations, the column is in the row for the
self-binding, and the column name contains the signature of the referenced
Binding. To return to our previous example, in our new schema the Binding
for java.lang.Object would have separate columns for its methods
named method:java.lang.Object#toString,
method:java.lang.Object#hashCode and so on. The column value
would either be empty (all the relevant information is contained in the name),
or perhaps a protocol buffer value could hold extra metadata.
Under this schema, any number of indexers can write the same column name and (possibly empty) value, interleaved in any order, with no locking: the write is idempotent.
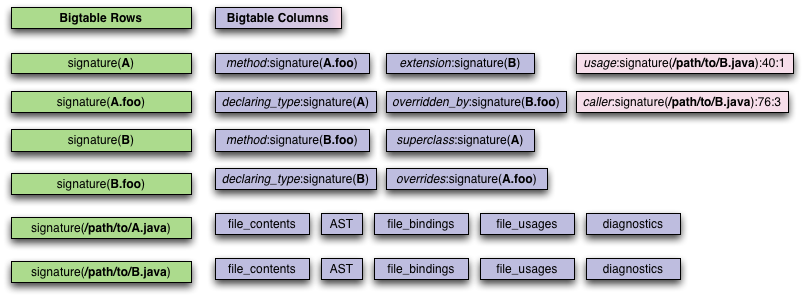
Here is a diagram of the proposed Bigtable representation for the code-graph example from the preceding section:
There are six Bindings total: two classes, two methods, and two files. There are eight mirrored Associations, two unidirectional usage Associations, and various collections of information gleaned about each of the files.
The diagram uses a hypothetical function called signature
that generates the global unique signature for a Binding. We use the
function both to save space in the diagram, and to give us wiggle room,
as the actual signature format has not yet stabilized.
In practice our signatures appear to be about 100 bytes on average.
The worst-case row size would occur for methods that have many callers.
java.lang.Object#hashCode is one such method. Under our
proposed scheme, we would approach the 100MB Bigtable row-size limit
beginning at perhaps 500,000 callers (allowing for some fragmentation
overhead in the column).
We can mitigate the potential row-size problem by doing a single MapReduce-like indexing pass over our code base without actually writing the data, keeping counts of associations, looking for the set of Bindings with the most columns. If any Bindings come even close to having 100,000 columns, we can think of at least five simple design modifications that would avert any chances of the problem occurring. We leave them as an exercise to the reader.
Aside from the possibility of hitting the row-size limit in rare edge cases, we see nothing inherently problematic with our lock-free design. There are of course many small details to work through, including what data to store and how to arrange it to maximize the Bigtable performance.
If you see any other problems with our design, please let us know.